|
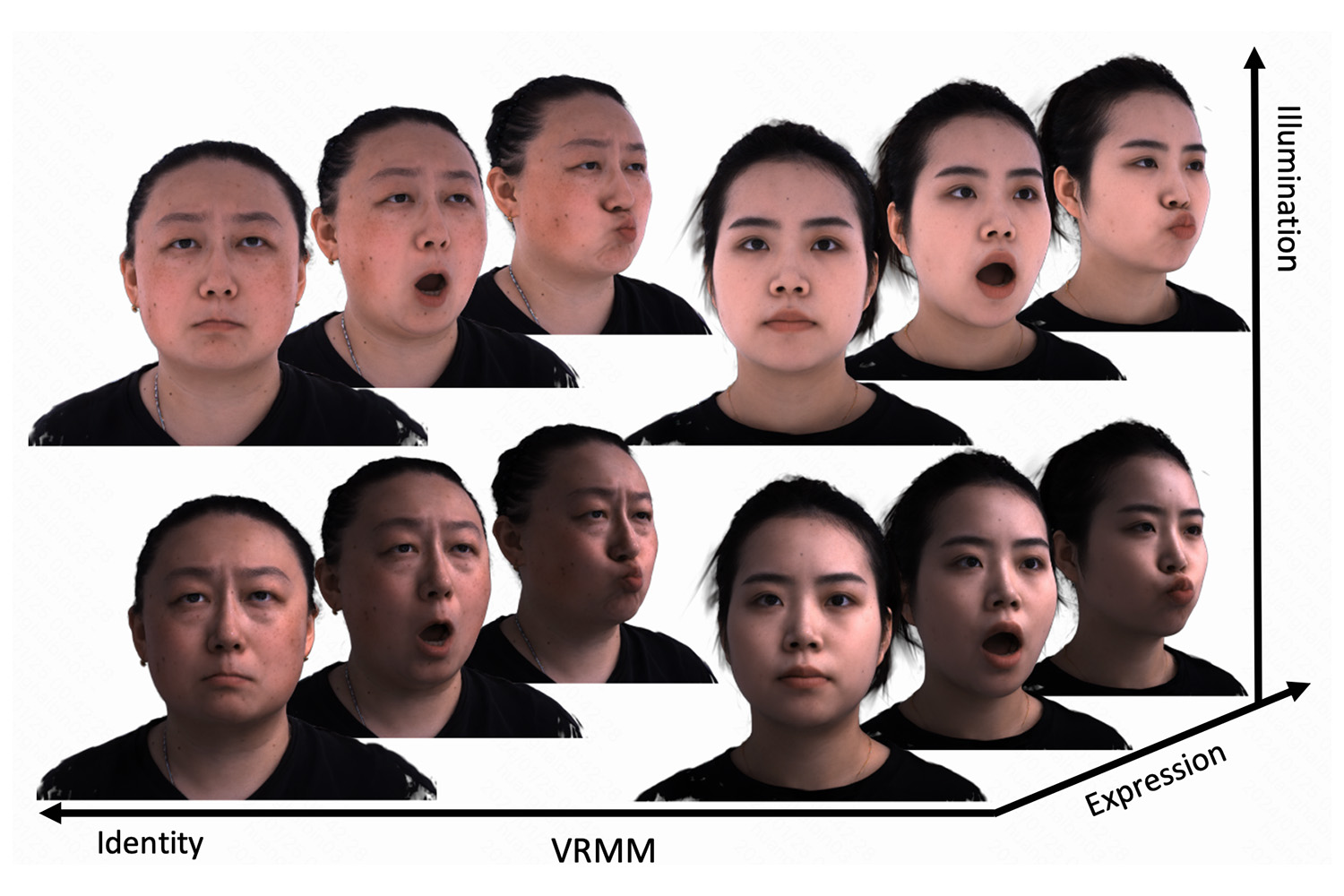
Haotian Yang | 杨皓天 I'm a Research Scientist at ByteDance working on video generation. Previously, I was a Research Engineer at Kuaishou Technology, where I worked on both video generation (as a core contributor to Kling video generation model) and 3D avatars (leading the development of a Light Stage system). I received the M.S. degree (under the supervision of Xun Cao and Hao Zhu) and B.S. degree from Nanjing University, in 2021 and 2018 respectively. My research interests lie in computer vision and computer graphics, including video generation and editing, human digitization, and 3D vision.
|

|